
画像
このページでは、顔画像の要件について説明します。
画像(image)は、すべての画像アップロード APIで必須のJSON形式のフィールドです。画像フィールドは、デコードされた画像データと多彩なオプションにより構成されます。それらを利用して、さまざまな利用目的を満たすことができます。検出APIの顔検出動作を除いて、他のすべての画像関連APIでは、同じような機能が提供されています。
モデルについてこのページは、最初の顔モデル「JCV_FACE_K25000」の仕様に基づいています。新しいモデルでは詳細が異なる場合があります。
今後、モデルの詳細を表示するインターフェースをいくつか提供する予定です。
画像要件
入力画像にはいくつかの要件があります。
- 画像ファイルのフォーマットは、JPG、PNG、GIFのいずれかであること(GIF を使用する場合、最初のフレームのみが処理されます)。
- 画像エンコード(Base64)のサイズは、約5MB未満であること(API ゲートウェイでの各リクエストによって制限されます)。
- 顔のサイズ(検出エリアで定義)は、32x32ピクセル以上で、画像全体の幅と高さの10%以上であること。
- 画像は白黒でないこと。
写真ファイルのサイズについて画像ファイルサイズの選定は、精度と遅延の妥協です。画像ファイルのサイズが大きいほど、顔の品質が高くなり、顔認識の精度が高くなります。一方、画像が大きいほど処理に時間がかかるため、遅延が増大します。
ベストプラクティスとして、顔のサイズが200x200ピクセルを超える高品質、正面の画像を使用することを推奨します。また、デコードする前に、画像をトリミングして200KB未満に圧縮することを推奨します。
画像データ
APIで送信されるすべての画像データは、base64でエンコードする必要があります。AnySeeでは、その機能を提供しません。ご自身のサービスに実装してください。ここでは、base64エンコーディングの2つの簡単な例を提供します。
import base64
# ファイルを読み取り、バイナリをbase64文字列に変換
def base64_encode_file(file_path):
handle = open(file_path, "rb")
raw_bytes = handle.read()
handle.close()
return base64.b64encode(raw_bytes).decode("utf-8")$ base64 file_path
画像ファイルの保存についてAnySeeでは、ユーザーがアップロードした画像ファイルまたは画像データは、いかなる状況でもどこにも保存されません。Base64エンコードされた画像データは、検出または特徴抽出後に即破棄されます。調査目的のため画像ファイルが必要な場合は、画像データベースを独自で構築する必要があります。
エンコードされた文字列は、文字列値としてimage.dataフィールドに入れてください。省略したりNullにしたりすると、エラーが発生します。以下は短縮された例です。
{
"image": {
"data": "/9j/4AAQSkZJRgAB="
}
}エリアと検出
AnySee は、画像内の検出エリアを長方形で絞り込むことができます。areaフィールドに4つの整数値を使用して指定できます。
{
"area": {
"top": 0,
"left": 0,
"width": 1000,
"height": 1000
}
}このareaフィールドが設定されている場合、顔検出モデルは、長方形の検出エリアと重なっている顔のみ検出・処理します。 顔エリアの定義については、位置を参照してください。
顔検出ロジックは、画像が必要なAPI間でわずかに異なります。顔検出APIは、画像内(エリア指定ある場合は検出エリア内)のすべての顔を検出します。他のAPIは、画像内(エリア指定ある場合は検出エリア内)の最大の顔のみを検出・処理します。
AnySeeには2つの検出モデルがあります。一つの顔のみ検出必要がある「高速モデル」と、複数の顔を検出する必要がある「低速モデル」となります。異なるAPIは、応答時間と検出精度を最適化するため、異なる検出ロジックを使用しています。そのため、位置と角度などの詳細な顔情報にわずかな違いが生じます。
| API | 最初に使用するモデル | 次に使用するモデル | 顔検出数上限 |
|---|---|---|---|
| POST /entities/faces | 高速モデル | 低速モデル | 1 |
| PATCH /entities/faces/{$uuid} | 高速モデル | 低速モデル | 1 |
| POST /entities/faces/search | 高速モデル | 低速モデル | 1 |
| POST /entities/faces/detect | 低速モデル | - | 複数可能 |
| POST /entities/faces/compare | 高速モデル | 低速モデル | 1 |
| POST /entities/faces/{$uuid}/compare | 高速モデル | 低速モデル | 1 |
自動回転
リソースを消費するプロセスこのオペレーションは、標準のリクエストよりも余分なリソースを消費するため、遅延が高くなります。
機能を十分に理解した上でご利用ください。
画像のExif(エクスチェンジャブル・イメージ・ファイル・フォーマット)メタデータに画像の向き情報が含まれている場合があります。通常、OSは画像を表示するときにExif情報に従って自動的に向きを調整するため、画像が縦向きになっていることを誤解されやすいです。これらの画像をそのままエンコードされてサービスに送信されると、多くの場合では、モデルが認識できず、顔が見つからないエラーを返します。まれに、間違った向きの画像がモデルによって受け入れられ、誤って処理される可能性があります。その場合の認識精度は保証できません。

向き情報付きのExif例
間違った向きの画像を入力することを避けるために、画像データを送信するときにautoRotateフィールドをtrueに指定することで、システムは画像を正しい向きで自動的に調整して処理できます。
画像の登録時に自動回転を推奨しますお客様のシステムまたはアプリケーション側が入力画像を制御できないか、画像の前処理機能を持たない場合、自動回転機能を有効にすることを推奨します。特に顔データ追加のAPIを使用する場合は有効です。
レスポンスの詳細
AnySeeは、パワフルな顔認識機能を提供しています。一部のユーザーにとっては、全部の応答本文が冗長だと感じることがあります。また、各認証モジュールの処理に時間がかかり、ユーザー体験に影響します。当社のサービスでは、ユーザーが希望する詳細情報の種類を選択できるため、遅延とレスポンス内容を最適化できます。
returnDetailsフィールドには5つのオプションがあり、すべてが既定falseのブール値です。顔の詳細情報は、対応するフィールドがtrueに設定されている場合にのみ返されます。全部の情報を返す必要がある場合は、次のようにリクエストしてください。
{
"returnDetails": {
"position": true,
"angle": true,
"landmarks": true,
"quality": true,
"attributes": true
}
}位置、角度、ランドマーク
顔のアライメントとポーズは、顔特徴量と属性情報の抽出にとって、必要な手順です。位置、角度、ランドマークの3種類の出力は、高度な画像処理に役立ちます。returnDetailsのフィールドでレスポンスの個別指定を設定できます。
位置
positionフィールドには、顔認識の際に顔の位置を指定するエリアの4つの整数値により構成されます。topとleftの値は、左上の座標点のピクセル値となります。widthとheightの値を使用すると、画像内で顔エリア位置の長方形を指定できます。

顔位置とする顔エリア
上記の顔エリアの例から、額や耳など、顔認識のためにすべての顔パーツが必要とされていないことがわかります。逆に、顔エリア内の顔パーツは重要です。顔エリア内の顔パーツの遮蔽などの評価詳細については、品質情報を参照してください。
角度
「ポーズ」または「ヘッドポーズ」とも呼ばれる角度(angle)は、ピッチ(pitch)、ヨー(yaw)、ロール(roll)の名前で、顔が空間直交座標系のxyz軸からどのぐらいずれているかを評価する一連の値です。
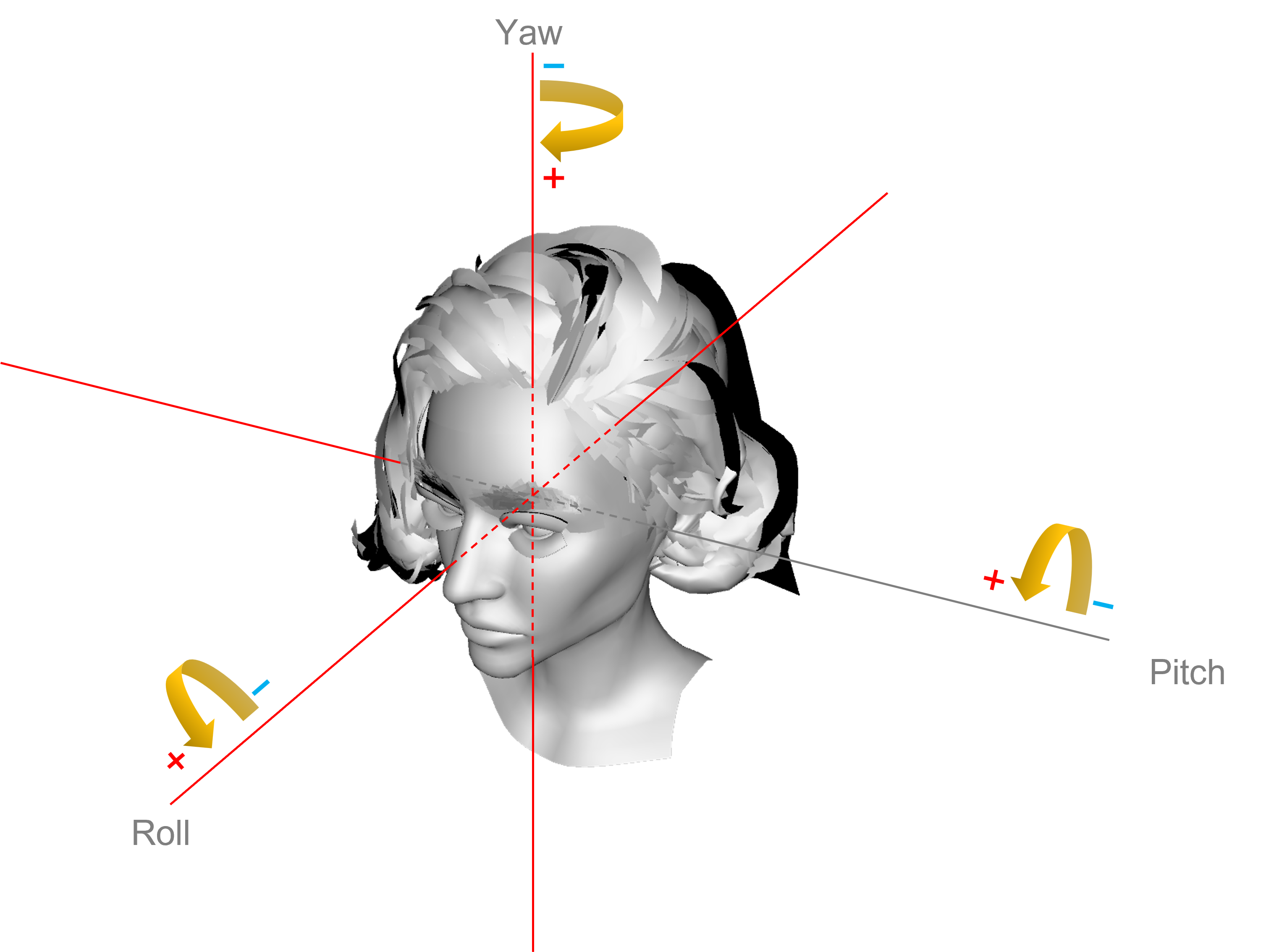
顔角度
これらの3つのパラメータの説明は次のとおりです。
| 名称 | 軸 | 値の範囲 | 方向 (+) |
|---|---|---|---|
| pitch | x | -90~90 | 下向き |
| yaw | y | -90~90 | 右向き |
| roll | z | -90~90 | 反時計回り |
これら3つの軸に加えて、複数の顔の画像内の幾何中心点を簡単に特定するために、2つの追加フィールドcenterXおよびcenterYもレスポンスされます。
ランドマーク
ランドマークは、顔のパーツを位置決めするためのポイントの集合です。各ランドマークポイントには、平面直交座標系の座標ポイントのピクセル値を表す整数のxとyにより構成されます。ランドマークは、AR(拡張現実)で顔に装飾を追加するシーンによく使用されます。AnySeeでは、106ポイントのランドマーク体系を使用しています。
レスポンスで返されるランドマークポイントの順序は、次の表に従います。
| 顔パーツ | 項目の順番 |
|---|---|
| 左眉 | [33, 34, 35, 36, 37, 64, 65, 66, 67] |
| 右眉 | [38, 39, 40, 41, 42, 68, 69, 70, 71] |
| 左目 | [52, 53, 72, 54, 55, 56, 73, 57, 74] |
| 右目 | [61, 60, 75, 59, 58, 63, 76, 62, 77] |
| 鼻 | [43, 44, 45, 46, 47, 48, 49, 50, 51, 80, 81, 82, 83] |
| 口 | [84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103] |
| 顔の輪郭 | [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32] |
左右についてこちらでの「左」と「右」は、画像における目と眉の位置を意味し、個人の視点からのものではありません。
各ランドマークの位置は、こちらの画像例も参照できます。

106個のランドマーク
品質情報
リソースを消費するプロセスこのオペレーションは、標準のリクエストよりも余分なリソースを消費するため、遅延が高くなります。
機能を十分に理解した上でご利用ください。
品質チェックは、顔を分析して、サイズ、明るさ、鮮明さ、遮蔽の度合いなどの定量情報を返します。より高い認識精度を得るために、顔データを追加する前に品質チェックを実行することを推奨します。
お客様の利用シーンに基づいて許容レベルをテスト・調整を行ってください。次の表は、各項目の詳細と、少々厳しめの基準の参考値について記載しています。
項目 | 説明 | 値の範囲 | 推奨範囲 |
|---|---|---|---|
brightness | 顔の明るさ。値が大きいほど明いです。 | -1.0 ~ 1.0 | -0.5 ~ 0.5 |
sharpness | MAGICアルゴリズムで顔の鮮明さ。値が高いほど鮮明です。 | 0.0 ~ 1.0 | 0.8 ~ 1.0 |
mouthClosed | 口が閉じている度合い。 | 0.0 ~ 1.0 | 0.6 ~ 1.0 |
centered | 顔の中心と画像の中心との距離。 値が高いほど近いです。 | 0.0 ~ 1.0 | 0.0 ~ 1.0 |
size | 画像全体に対する顔エリアの大きさ。(位置を参照してください。)値が高いほど大きいです。 | 0.0 ~ 1.0 | 0.0 ~ 0.85 |
integrity | 顔エリアが画像に含まれる度合い。値が高いほど良いです。 | 0.0 ~ 1.0 | 1.0 |
completeness.total | 各ランドマークの完成度(遮蔽が無い)の全体的な評価 | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
completeness.leftEyeBrow | 左眉が完全である度合い。値が高いほど良いです。 | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
completeness.rightEyeBrow | 右眉が完全である度合い。値が高いほど良いです。 | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
completeness.leftEye | 左目が完全である度合い。値が高いほど良いです。 | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
completeness.rightEye | 右目が完全である度合い。値が高いほど良いです。 | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
completeness.nose | 鼻が完全である度合い。値が高いほど良いです。 | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
completeness.mouth | 口が完全である度合い。値が高いほど良いです。 | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
completeness.faceContour | 顔の輪郭が完全である度合い。値が高いほど良いです。 | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
属性情報
リソースを消費するプロセスこのオペレーションは、標準のリクエストよりも余分なリソースを消費するため、遅延が高くなります。
機能を十分に理解した上でご利用ください。
AnySee は、最新のAIアルゴリズムを利用して有用な顔属性を抽出し、ユーザーが訪問者のデータを分析できるようにします。すべての値は推定値であるため、それらを事実の値として扱わないでください。
ageとemotionsを除いて、すべてのサブ項目には、1つ列挙文字列のvalueフィールドと、0.0から1.0の確実性(certainty)フィールドが含まれます。年齢(age)には3つの項目があり、上限(upperlimit)は年齢予測の最大値です。下限(lowerlimit)は上限から10を引いた値に等しく、推定値(value)は上限から5を引いた値に等しくなります。感情(emotions)フィールドには、8つのサブ項目とそれぞれの確実性(certainty)が含まれます。
| 項目 | 列挙値 | 説明 |
|---|---|---|
| age.value | - | 年齢:推定値 |
| age.upperlimit | - | 年齢:上限 |
| age.lowerlimit | - | 年齢:下限 |
| gender | male | 性別:男性 |
| gender | female | 性別:女性 |
| bangs | without_bangs | 前髪:前髪無 |
| bangs | with_bangs | 前髪:前髪有 |
| facialHair | without_facial_hair | 髭:髭無 |
| facialHair | with_moustache | 髭:口髭有 |
| facialHair | with_beard | 髭:顎髭有 |
| facialHair | with_sideburns | 髭:頬髭有 |
| helmet | without_helmet | ヘルメット:ヘルメット無 |
| helmet | with_helmet | ヘルメット:ヘルメット有 |
| hat | without_hat | 帽子:帽子無 |
| hat | with_hat | 帽子:帽子有 |
| headphones | without_headphones | ヘッドフォン:ヘッドフォン無 |
| headphones | with_over_ear_headphones | ヘッドフォン:耳覆い型ヘッドフォン有 |
| headphones | with_earbuds | ヘッドフォン:イヤホン有 |
| glasses | without_glasses | 眼鏡:眼鏡無 |
| glasses | with_transparent_glasses | 眼鏡:透明眼鏡有 |
| glasses | with_sunglasses | 眼鏡:サングラス有 |
| mask | without_mask | マスク:マスク無 |
| mask | with_nose_covered_mask | マスク:鼻カバーマスク |
| mask | with_mouth_covered_mask | マスク:口カバーマスク |
| mask | with_fully_covered_mask | マスク:フルカバーマスク |
| emotions | angry | 表情:怒り |
| emotions | happy | 表情:喜び |
| emotions | sad | 表情:悲しみ |
| emotions | calm | 表情:冷静 |
| emotions | surprised | 表情:驚き |
| emotions | scared | 表情:恐れ |
| emotions | disgusted | 表情:嫌悪 |
| emotions | sleepy | 表情:眠気 |
Updated 11 months ago