
Image
This page provides detailed information on face images.
The image is a required JSON-formatted field for all image-uploading APIs. It includes the decoded image data and other valuable options to fulfill various requirements. Except for the Detect API's face detection behavior, all other image-related functions are identical across all APIs.
About modelThis page is based on the first facial model, "JCV_FACE_K25000". Details may differ in the new models.
Refer to the GET /models endpoint for more details on the capability of each model.
Image requirements
There are several requirements for the input image.
- The image file format should be one of JPG, PNG, and GIF (When using GIF, only the first frame will be processed).
- The image string (in base64) size should generally be smaller than 5MB. (Restricted by each request at the API gateway).
- The face size (defined by the bounding box) should be more than 32 x 32 pixels and more than 10% of the image's width and height.
- The image should be colored.
About image file sizeThe image file size choice is a tradeoff between accuracy and latency. A larger image file size means higher face quality, leading to higher precision in facial recognition. Meanwhile, a larger image takes more time to process, thus causing a higher latency.
As the best practice, we recommend using high-quality frontal clear images with a face size of over 200x200 pixels. Also, trim the image and compress it to less than 200KB before decoding.
Image data
All image data sent via APIs should be base64 encoded. AnySee does not provide this function. Please implement it in your services. Here we provide two simple examples of base64 encoding.
import base64
# Read the file and convert the binary to a base64 string
def base64_encode_file(file_path):
handle = open(file_path, "rb")
raw_bytes = handle.read()
handle.close()
return base64.b64encode(raw_bytes).decode("utf-8")$ base64 file_path
About image storageIn AnySee, user uploaded image file or image data will not be stored anywhere in any condition. Image data in base64 encoding is disposed after detection or feature extraction. For the investigation purpose, users should prepare their own image storage database.
The encoded string should be put in the image.data field as a string value. Missing it or leaving it blank will lead to errors. Here is a shortened example.
{
"image": {
"data": "/9j/4AAQSkZJRgAB="
}
}Area and detection
AnySee allows users to narrow down the detection area of the Image by a rectangle area. You can specify it by using four integer values in the area field.
{
"area": {
"top": 0,
"left": 0,
"width": 1000,
"height": 1000
}
}If this area field is set, the face detection model will only focus on the faces with their facial area overlapping the rectangle area. To define the facial area, please refer to the Position section.
The face detection logic differs slightly among all the APIs requiring image upload. The Detect API detects all faces in the image (or the rectangle area if specified). Other APIs will only deal with the largest face in the image (or the rectangle area if specified).
There are two detection models in AnySee, a fast model used in a single-face scenario and a slow model capable of detecting multiple faces. Different APIs use different detection logics to optimize the response time and detection accuracy, leading to slight differences in the detailed face information of position and angle.
| API name | First try | Second try | Face number |
|---|---|---|---|
| POST /entities/faces | Fast model | Slow model | 1 |
| PATCH /entities/faces/{$uuid} | Fast model | Slow model | 1 |
| POST /entities/faces/search | Fast model | Slow model | 1 |
| POST /entities/faces/detect | Slow model | - | Multiple if applicable |
| POST /entities/faces/compare | Fast model | Slow model | 1 |
| POST /entities/faces/{$uuid}/compare | Fast model | Slow model | 1 |
Auto rotation
Resource-consuming processThis operation consumes extra resources than a standard request, leading to higher latency.
Please use it only when you understand the function thoroughly.
Images sometimes include orientation information in their Exif (Exchangeable image file format) metadata. OS will usually automatically adjust the orientation according to the Exif information when displaying the image, causing a misconception that the image is in the portrait orientation. If this image is encoded and sent to the service, the model usually cannot recognize it and return a face not found error. Possibly, the model accepts the wrong-oriented image and gets wrongly processed. Recognition accuracy cannot be guaranteed under those circumstances.

Exif with rotation information
To avoid inputting a wrong-oriented image, you can specify the autoRotate field as true when posting the image. The system will automatically detect and process the image in the correct orientation.
Use auto rotation when registering an imageSuppose your system or application has no control over the inputting image or does not have any pre-processing capabilities. We recommend enabling this function when posting the image, especially in the Create API.
Return details
AnySee provides plenty of powerful facial recognition functions. Sometimes the full response might be redundant for some users. Also, processing the image with all function modules takes longer, causing worse user experiences. Our service lets users choose the exact detailed information to return, optimizing the response time and contents.
There are five options in the returnDetails field, each being a boolean with the default value of false. The detailed information will only return when the corresponding field is set to true. Here is an example of requiring to return complete information.
{
"returnDetails": {
"position": true,
"angle": true,
"landmarks": true,
"quality": true,
"attributes": true
}
}Position, angle, and landmarks
Face alignment and head pose are required steps for feature and attribute extraction. The three types of outputs, position, angle, and landmarks, can also be helpful for advanced image processing. Each can individually set its return option in the returnDetails field.
Position
The position field contains four integer values to position the face used for facial recognition. The top and the left values stand for the top coordinate point's pixel values. With the width and the height values, it is possible to get a bounding box of where the face area is located in the image.

Positioning bounding box
From the bounding box example, you can learn that not all face parts must be visible for facial recognition, like your forehead or ears. But on the contrary, the face parts inside the bounding box are crucial for the process. For more details on evaluating the occlusion of face parts inside the bounding box, please refer to Quality.
Angle
Also usually called pose or head pose, the angle is a set of values describing how much the face deviates from the x, y, and z axes in pitch, yaw, and roll.
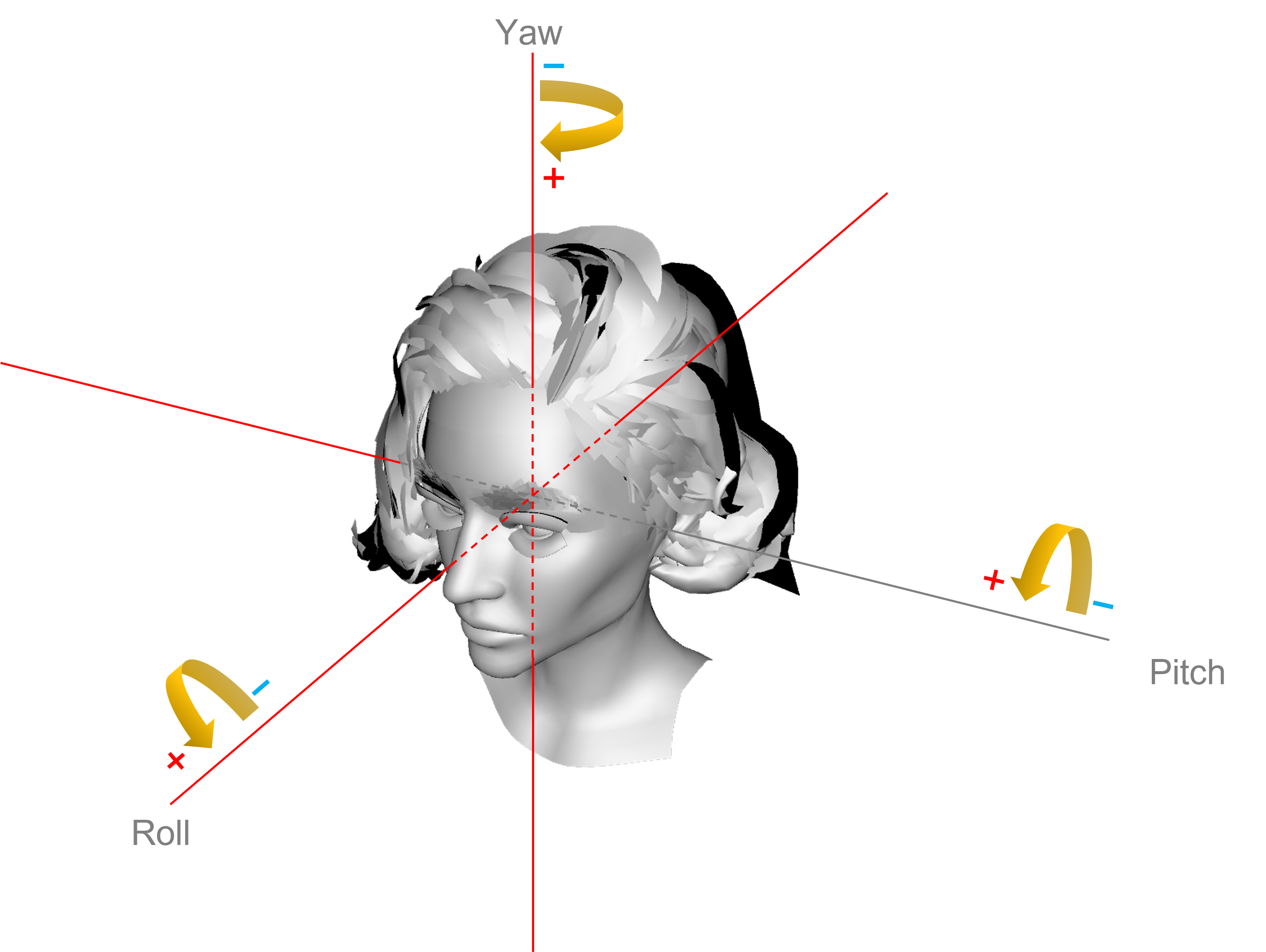
Head angle (pose)
The description of the three parameters is as follows.
| Name | Axis | Range | Orientation (+) |
|---|---|---|---|
| pitch | x | -90~90 | Heading down |
| yaw | y | -90~90 | Heading right |
| roll | z | -90~90 | Heading counter-clockwise |
In addition to these three axes, two extra fields centerX and centerY are also returned to pinpoint the geometric center points in a multiple-face image easily.
Landmarks
Landmarks are a set of points to position the facial parts of a face. Each of the points contains an x and a y integer, representing the pixel value of each coordinate point. Landmarks are commonly used in AR (Augmented Reality) to add some face decorations. AnySee uses a 106-point landmark system.
The returning order of landmarks in the response is strictly consistent with the following table.
| Face part name | Order No. |
|---|---|
| Left eyebrow | [33, 34, 35, 36, 37, 64, 65, 66, 67] |
| Right eyebrow | [38, 39, 40, 41, 42, 68, 69, 70, 71] |
| Left eye | [52, 53, 72, 54, 55, 56, 73, 57, 74] |
| Right eye | [61, 60, 75, 59, 58, 63, 76, 62, 77] |
| Nose | [43, 44, 45, 46, 47, 48, 49, 50, 51, 80, 81, 82, 83] |
| Mouth | [84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103] |
| Face contour | [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32] |
About Left and Right
LeftandRighthere means the position of eyes and eyebrows in the image, not from the person's own perspective.
You can also refer to the image example to better understand each landmark's location.

106 Landmarks
Quality
Resource-consuming processThis operation consumes extra resources than a standard request, leading to higher latency.
Please use it only when you understand the function thoroughly.
Quality check analyzes and returns quantitive values of face size, brightness, sharpness, occlusion, etc. It's highly recommended to performant quality checking before adding face entities to get higher recognition precision.
We highly recommend testing and adjusting the acceptance level based on your use scenario. The following table shows the details of each item, together with reference values of a rather strict standard.
| Item | Description | Possible range | Recommended range |
|---|---|---|---|
| brightness | How bright the face is; The higher the brighter. | -1.0 ~ 1.0 | -0.5 ~ 0.5 |
| sharpness | How clear the face is calculated by the MAGIC algorithm; The higher the clearer. | 0.0 ~ 1.0 | 0.8 ~ 1.0 |
| mouthClosed | How close the mouth is closed; The higher the more closed. | 0.0 ~ 1.0 | 0.6 ~ 1.0 |
| centered | How close the center of the face is to the center of the image; The higher the more closer. | 0.0 ~ 1.0 | 0.0 ~ 1.0 |
| size | How big the face area (Refer to Position) is, compared to the total image; The higher the bigger. | 0.0 ~ 1.0 | 0.0 ~ 0.85 |
| integrity | How much the face area is included in the image; The higher the better | 0.0 ~ 1.0 | 1.0 |
| completeness.total | The overall evaluation of how complete (without occlusion) each Landmarks is; The higher the better. | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
| completeness.leftEyeBrow | How complete the left eyebrow is; The higher the better. | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
| completeness.rightEyeBrow | How complete the right eyebrow is; The higher the better | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
| completeness.leftEye | How complete the left eye is; The higher the better | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
| completeness.rightEye | How complete the left eye is; The higher the better | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
| completeness.nose | How complete the nose is; The higher the better | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
| completeness.mouth | How complete the mouth is; The higher the better | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
| completeness.faceContour | How complete the face countour is; The higher the better | 0.0 ~ 1.0 | 0.9 ~ 1.0 |
Attributes
Resource-consuming processThis operation consumes extra resources than a standard request, leading to higher latency.
Please use it only when you understand the function thoroughly.
AnySee utilize the latest AI algorithm to extract valuable face attributes for users to analyze data of their visitors. All values are based on estimation, so do not treat them as the grand truth.
Except for age and emotions, every sub-item contains one value field of enumeration string and a corresponding certainty field ranging from 0.0 to 1.0. The age includes three items, where the upperlimit is the maximum value of the age-predicted. The lowerlimit equals upperlimit subtracted by 10, and the value equals upperlimit subtracted by 5. The emotions field lists 8 sub-items and their certainty.
| Item | Enumeration |
|---|---|
| age.value | - |
| age.upperlimit | - |
| age.lowerlimit | - |
| gender | male |
| gender | female |
| bangs | without_bangs |
| bangs | with_bangs |
| facialHair | without_facial_hair |
| facialHair | with_moustache |
| facialHair | with_beard |
| facialHair | with_sideburns |
| helmet | without_helmet |
| helmet | with_helmet |
| hat | without_hat |
| hat | with_hat |
| headphones | without_headphones |
| headphones | with_over_ear_headphones |
| headphones | with_earbuds |
| glasses | without_glasses |
| glasses | with_transparent_glasses |
| glasses | with_sunglasses |
| mask | without_mask |
| mask | with_nose_covered_mask |
| mask | with_mouth_covered_mask |
| mask | with_fully_covered_mask |
| emotions | angry |
| emotions | happy |
| emotions | sad |
| emotions | calm |
| emotions | surprised |
| emotions | scared |
| emotions | disgusted |
| emotions | sleepy |
Updated 11 months ago